



用 GPT Image2 做完一个真实 UI 项目后,我发现 AI 最难的不是出图,而是如何成为可控、稳定、能被设计师调度的工具。

大家好,我是风筝 KK。
24 年初,我曾经和大家分享过AI 如何融入敏捷开发,为设计提效。
那时候,我关注更多的是“效率”。
因为在真实工作里,团队采用敏捷开发,两周一个迭代,留给设计师做需求分析和方案设计的时间,往往只有三四天。
时间一紧,设计师最先牺牲掉的,往往不是交付,而是思考。
所以那时候,我开始把 AI 放进设计工作流里,用它帮我做需求拆解、资料整理、文案补充、方案初稿。
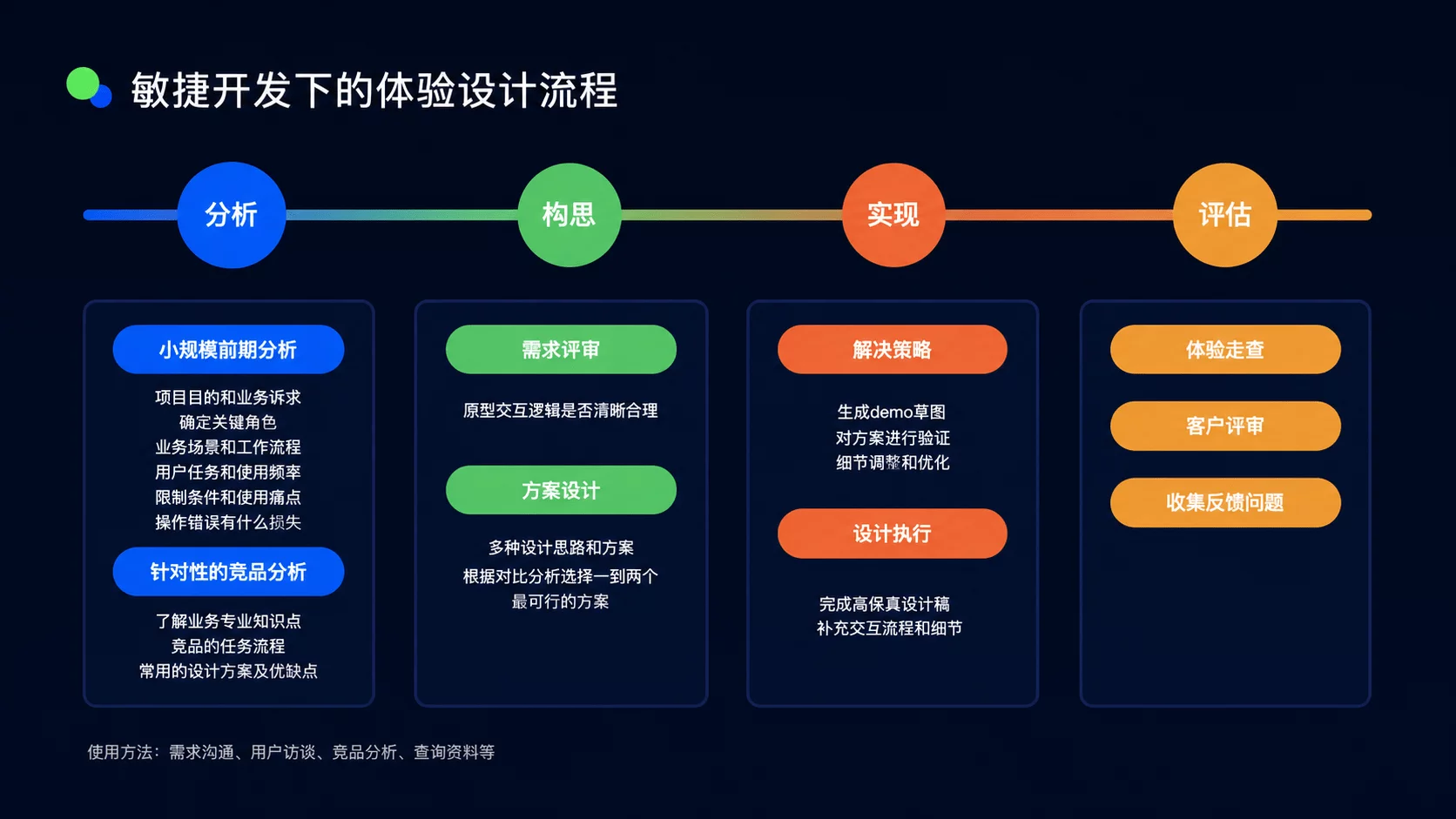
目的很简单:
先把重复的、结构化的工作提效,再把时间留给真正需要判断的地方。
但最近这半个月,我在项目里密集使用 GPT Image2 做 UI 方案发散后,又有了一个新的感受。
AI 对设计的影响,已经不只是“帮我们快一点”了。
它开始进入更前面的设计环节,比如前期的需求分析、针对性的竞品分析、需求评审、方案探索、方案验证、设计执行等。
过去这些内容,设计师通常需要自己找参考、反复做方案尝试。
现在 GPT Image2 几句话就能先生成一批方向。
一开始,我也觉得挺惊艳,我仅说了一段话,Image2 就给我生成了这样的效果。
提示词:给我生成体重监测 APP 的全套界面,APP 界面里面有粉色的卡通猫作为装饰,【设计风格 ios26 的玻璃风格】【手绘风格】,按钮宠物特点元素,比例 9:16.
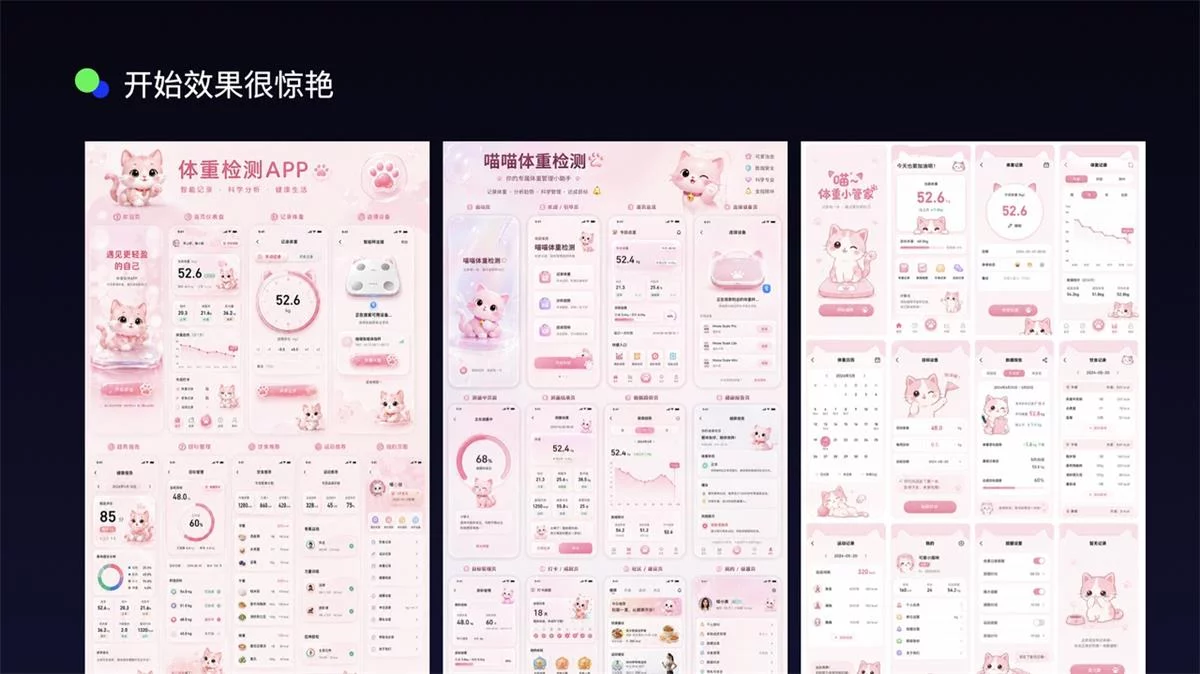
不仅如此,给它一个草图,它能生成页面,给它一张参考图,它能迁移风格,给它一个模糊描述,它能给出几种视觉方向。
但真正放到项目里用了一段时间后,我发现一个问题:
GPT Image2 会出图,不代表它真的会做 UI。
很多图第一眼完整、好看,但放回真实项目里,会发现它更像概念图,不像真实 App;光效很丰富,但信息层级不清楚;页面看起来完整,却可能自动加了业务里没有的模块。
所以这篇文章,我不想单纯分享“GPT Image2 怎么出图”。
我更想聊聊:
当 AI 已经很会生成画面之后,UI 设计真正难的,变成了什么?
真正难的不是让 AI 生成一张图。
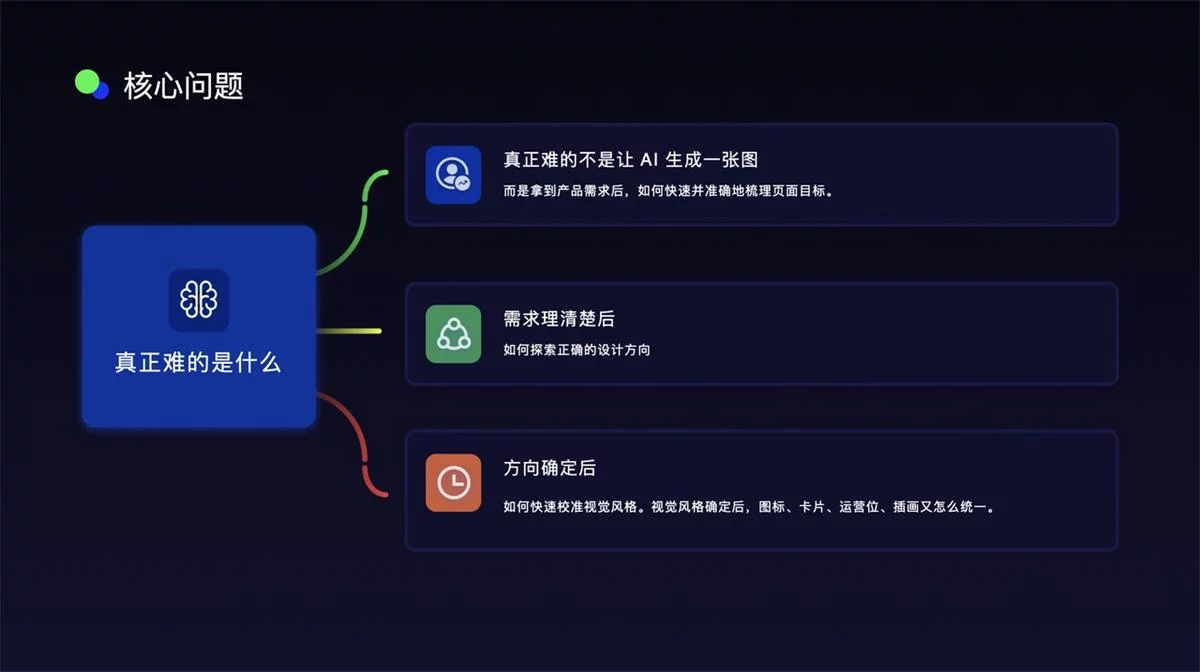
而是拿到产品需求后,如何快速并准确地梳理页面目标。
需求梳理清楚后,如何探索正确的设计方向。
方向大概确定后,如何快速校准视觉风格。
视觉风格确定后,图标、卡片、运营位、插画又怎么统一。
简单来说,就是如何把 AI 放进整个 UI/UX 工作流中,而不是只把它当成一个生图工具。
我希望它最终能帮设计师达到这几个目标:
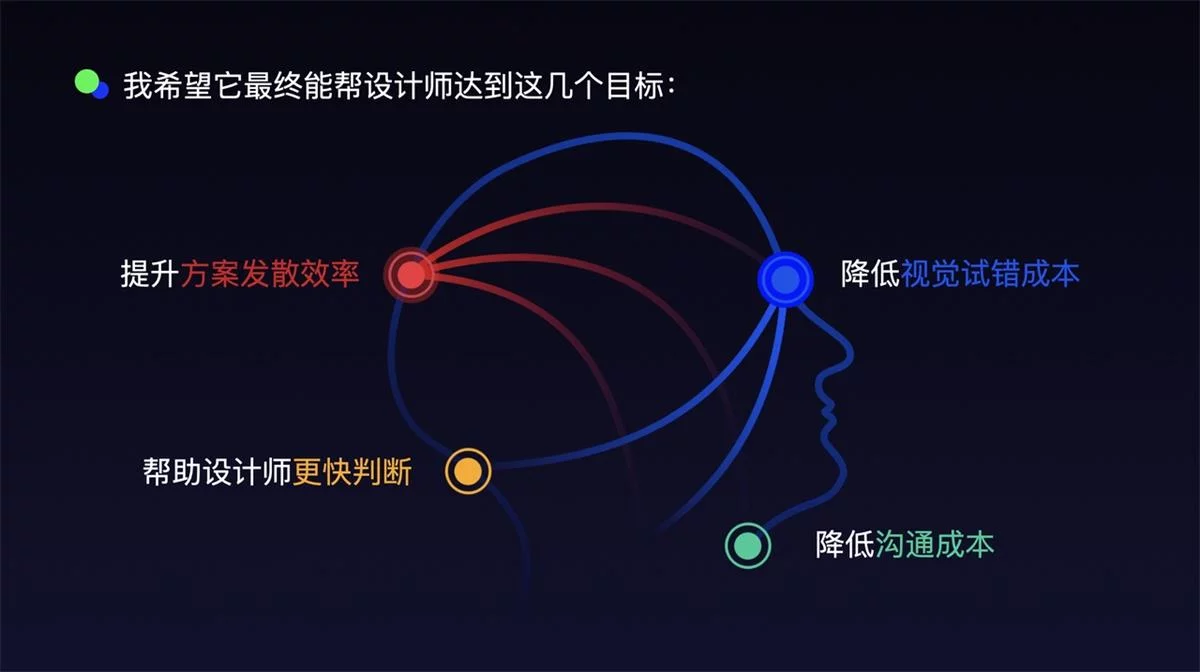
提升方案发散效率,降低视觉试错成本,降低沟通成本,帮助设计师更快判断。
但前提是:
AI 的输出要足够稳定。
如果 AI 生成的内容本身不稳定,我们直接去搭自动化流程,其实意义不大。
因为自动化不是目的。
自动化最后要产出有质量、可判断、可继续推进的内容。
如果只是把不稳定的结果更快地产出来,那不是提效,反而会增加返工。
所以这半个月我最大的变化是:
先让 GPT Image2 在单点能力上稳定下来,再考虑把它串进完整的设计工作流。
这半个月用下来,我遇到的问题主要集中在四类。

1. 输入模糊,容易跑偏
比如:如果你要做一个高端金融行业服务升级的启动页。
不要只说:
“金融一点、尊贵一点、有服务感。”
这些词设计师自己能理解,但 AI 不一定知道在当前项目里应该怎么落地。
我会把它拆成更具体的设计语言,比如:
页面尺寸为 iPhone 截图比例,保留状态栏,750×1624。 页面要像高端金融会员 H5 邀请函开场,不要像海报。 背景可以用深色高级底,但不要恐怖、压抑。 光效用柔和香槟金,少量贵族紫弥散光。 整体要温暖、向上、有生命力、有欢迎仪式感。 文字居中,标题精致但不要过大。 留白充足,页面要有真实 App 截图感。 同时明确禁止项:不要大金字、厚重阴影、恐怖黑暗、保险柜压迫感,也不要丧葬、宗教、末日氛围。 你看,这就不是简单在写提示词了。 这是把设计师脑子里的判断,翻译成 AI 能执行的规则。
2. AI 太会发挥
GPT Image2 很容易生成丰富的光效、装饰、3D 元素。
如果只是做概念图,这些可能挺好看。

但放到真实 App 页面里,很多时候更需要轻量、清晰、可落地。
比如一个人脸识别页面,AI 可能会生成很炫的背景、很立体的卡片、很丰富的图标。
但用户真正关心的可能只是:
为什么要做人脸识别,我的资料安不安全,识别时遇到异常怎么提示等。
如果这些信息没有被清楚表达,再漂亮的画面也只是视觉效果。
所以我现在会提醒自己:
AI 很擅长“表现”,但 UI 设计更需要“克制”。
页面不是越满越好,光效不是越多越高级,插画不是越大越有记忆点。
真实 UI 首先要让用户看懂,让操作明确,让信息能被承载。
3. 多轮修改容易变形
这是我踩坑最多的地方。很多时候,我只是想改一个小地方。
比如:
背景光效弱一点。
按钮不要太厚。
主视觉小一点。
图标不要太卡通。
卡片阴影轻一点。
但 Image2 的修改不太像 Figma 里的精修,它经常会在改一个地方时,顺手把整张图都重新生成。

结果就是:
按钮变好了,背景变了。
背景变好了,卡片变了。
主视觉变好了,页面结构又乱了。
所以如果一直整图反复修改,很容易越改越失控。
后来我更倾向于拆模块调整。
背景单独生成,按钮单独调整,图标单独试风格,主视觉单独优化,卡片样式单独对比。
每次只让 AI 解决一个问题,反而更稳定。
4. 好看不等于落地
AI 图经常第一眼挺好看,但真实项目里,最后还要回到 Figma 里重构。
你要看:
字号能不能统一。
间距能不能还原。
按钮比例是否合理。
卡片组件能不能复用。
图标风格是否统一。
前端实现成本高不高。
内容是否符合业务规则。
所以 GPT Image2 生成的图,更多是方向参考,它不能直接替代最终设计稿,如果设计师没有做二次判断和重构,很容易把“方向图”误当成“交付稿”。
所以 GPT Image2 提高的是发散速度,但设计师必须提高收敛能力,否则 AI 只会生成更多选择噪音。
经过这半个月的深度使用,我现在会把它收敛成四个动作:
先分析,再参考,先发散,再收敛。
1. 先分析:别急着出图
1)前期分析阶段
在前期分析阶段,我会把我了解到的产品需求、业务背景、用户场景,以及我自己主观上的判断,先全部喂给 GPT。

这一步不是为了让 AI 直接给页面方案,而是先让它帮我做需求分析。
比如我会让它判断:
这个项目到底要解决什么问题?
业务目标是什么?
用户目标是什么?
页面的第一性原理是什么?
最核心的用户任务是什么?
最该优先解决的 20% 问题是什么?
如果引入 AI,AI 应该放在哪个环节?
如果产品还在讨论阶段,我也会让它先帮我做产品定位。
这一步的价值是,先把模糊的信息结构化。
很多时候,需求文档里写的是功能,但设计师真正要判断的是:
为什么做,给谁用,解决什么问题,这个页面到底要推动用户完成什么。
如果这一步不清楚,后面出图越快,越容易跑偏。
所以我现在会先让 GPT 帮我把问题拆开,再进入视觉方案。
具体如何进行产品定位,可以查看我之前和大家分享的《以智能客服管理平台为例,手把手教你如何用 AI 定义设计问题》文章后面有详细的提示词,大家可以直接使用。
2)需求评审
需求评审阶段,我也会让 GPT 先帮我过一遍。
因为很多需求在评审时,看起来是一个页面问题,但背后其实可能是业务规则、权限、数据、状态、异常没想清楚。
所以当你把需求背景、任务角色、产品目标、老板的想法等喂给 AI 后,我会让 AI 帮我提前检查几个问题:


然后 AI 会帮你提前判断:
这个需求是不是清楚?
规则是不是完整?
有没有缺状态?
有没有隐藏风险?
这个页面是否真的需要做?
有没有更轻的实现方式?
AI 可以帮我先扫一遍,让我在评审时更快抓到问题。
2. 再参考:不要让 AI 凭空发挥
进入方案前,我一般还会让 AI 帮我做一轮竞品分析。
但这里的竞品分析,不是让 AI 直接替我下结论。
因为目前 AI 还是会有幻觉,尤其是具体竞品和细节上,不适合完全依赖它。
我现在更常用的方式是,让它帮我寻找竞品方向,并根据我们的业务目标,整理出一张分析表。

然后我再根据这张表,逐一去体验真实产品。
我会重点看几个维度:
竞品怎么组织信息。核心入口放在哪里;主操作怎么设计;不同状态怎么展示;异常情况怎么收口;哪些设计可以借鉴;哪些不适合照搬。
如果是 AI 相关产品,我还会额外看:
AI 入口是主入口还是辅助入口;输入引导是否清楚;结果呈现是否结构化;任务是否真的闭环;低置信度、失败、权限不足时有没有兜底。
这一步的目标不是做一份很厚的竞品报告,而是帮我回答一句话:
这个方向,行业里通常怎么做?我们应该借鉴什么,又应该避开什么?
这里也包括参考图:
当我们关键词不够清晰时,什么形容词都不如几张对的参考图来得快。
就像自己做图一样,先找风格参考,再找结构参考。
你可以告诉 GPT Image2:
参考图 1 的视觉风格,参考图 2 的页面结构。
这样它生成的方向通常会比凭空想象更稳定。
3. 做发散:让 AI 先跑多个方向
前面几个阶段做完之后,再进入 GPT Image2 的方案发散。
这个阶段,我现在主要会用四种方式。
1)模糊需求出多方案。
当需求还不够清晰时,我不会只让它出一张图,而是会让它出 3 个方向。
比如做一个金融 App 首页,可以先尝试:

黑金轻透版。
白金轻奢感。
创意空间版。
这样做的好处是,团队可以先基于画面讨论:到底要更像工具、更像服务,还是更像活动运营。
它的价值不是让 AI 帮你决定方向,而是让你更快看到有哪些可能性。
2)参考风格定调性。
当视觉风格还没收敛时,我会让 GPT Image2 参考某类 App 的设计语言,快速校准方向。
比如你想参考滴滴的风格,就不要只说“参考滴滴”。
你可以拆得更具体:
参考它的浅色背景、卡片层级、按钮比例、图标克制感、运营位轻量感。
这样 AI 学到的是设计语言,而不是表面颜色。
3)基于垫图改风格
当已有初稿但风格不合适时,可以用 GPT Image2 做快速调整。
比如:
太卡通,就降低 Q 版感。
太重,就减少投影和复杂背景。
太 3D,就改成轻量扁平。
不够像 App,就降低装饰,突出信息承载。
运营感太强,就弱化氛围,强化内容层级。
这个方式主要用于快速判断:
当前方向是否值得继续深化。
如果 AI 改完之后,方向明显变好,就可以回到 Figma 里继续精修。
如果改了几轮还是不对,说明可能不是风格问题,而是结构或定位本身需要重新判断。
4)草图转视觉方案
当只有手绘草图或粗略想法时,也可以用 GPT Image2 快速生成视觉草案。
比如你在做金融首页时,AI 生成的结构总是不符合预期,这时候可以先手绘一个大体结构:顶部导航、中间主卡片、下面功能入口、底部主按钮。
然后再告诉 AI:根据这个结构,参考支付宝基金类页面的设计风格输出效果图。
这样做的价值是,让模糊想法先变成可以讨论的画面。
它不需要完美。
它的作用是帮助团队快速判断:结构是否成立,信息层级是否合理,风格是否值得继续深化。
4. 再收敛:回到判断和落地
1)让 AI 帮我分析每个方案优缺点
当设计方案已经有了 2-3 个方向后,我会让 AI 再帮我做一轮视觉诊断。这一步不是让 AI 决定哪个方案最好,而是让它帮我把问题拆出来。
比如两个方案都挺好看,一个更有氛围,但信息被弱化;一个更克制,但视觉记忆点不够。
这时候 AI 可以先帮我从信息层级、页面结构、视觉风格、卡片样式、图标统一性、按钮比例、光影氛围、落地成本几个维度分析差异。
最后再由我判断哪个更适合当前目标,所以视觉诊断这一步,AI 不是评委,它更像一个帮我拆问题的助理。
2)Figma MCP 还不稳定
到了设计执行阶段,我也尝试过让 GPT 通过 Figma MCP 直接把方案落到 Figma。
但目前我的体验是:还不够稳定。
如果只是让它 1:1 还原效果图,页面结构、组件比例、细节还原都不太理想。
所以目前在我的 UI 工作流里,我更习惯这样用:GPT Image2 负责生成方向图,设计师负责判断和收敛,Figma 负责最终重构和交付。即梦这类工具可以辅助生成局部素材,比如图标、插画、背景元素。
这样反而更省钱,也更稳定。
目前对我来说,一个 GPT Plus 基本就能覆盖前期大部分方案发散和视觉探索。
AI 不是直接替我完成整套设计稿,而是帮我减少无效试稿。
3)评估阶段
至于设计评估阶段,目前我还没有完全把 AI 加进去。
比如测试用例、交互验收、页面状态检查,我很多时候还是手写更快。
原因很简单:
这个阶段需要非常明确的规则,而 AI 有时候太发散,不够收敛。
如果前面的交互规则我已经整理清楚,手写测试点和验收点反而更直接。
当然,后续这里也可以继续探索。
比如让 AI 根据交互文档帮忙检查:
是否缺少空状态、错误状态、权限状态、操作反馈,是否有文案不一致,是否有前后流程不闭环。
但目前对我来说,它还不是最高优先级。
这段时间用下来,我觉得 GPT Image2 对 UI 设计最明显的价值,不是替代设计师,而是帮助设计师更快进入判断。
1. 发散更快
过去在时间紧的情况下,可能只能做 1-2 个方向。
引入 GPT Image2 后,可以更快看到多个可能性,再由设计师进行筛选和收敛。
它的价值不是更快出最终稿,而是更快完成前期方向探索。
2. 试错更低
一些风格轻重、图形比例、构图关系,不需要一开始就在 Figma 里完整绘制。
可以先通过 AI 快速试插画轻重、背景复杂度、颜色氛围、图标风格、卡片形式、运营感强弱。
这样可以减少无效试稿。
3. 沟通更快
很多设计描述本身比较抽象。
比如:金融一点\轻量一点\不要太卡通\更有服务感\不要太抢主视觉。
以前大家只能靠语言想象。
现在先用 GPT Image2 生成方向图后,团队可以基于画面讨论。
不是讨论“你理解的高级”和“我理解的高级”。
而是直接讨论:这张图哪里对,哪里过了,哪里可以保留,哪里需要收掉。
4. 判断更快
AI 生成多个方向后,设计师可以更快对比:
哪个更符合业务目标,哪个更适合页面位置,哪个更符合品牌调性,哪个信息层级更清楚,哪个更容易前端落地。
所以 GPT Image2 并不是替代设计判断,它是帮助设计师更快进入判断。
最后说一下我接下来想继续探索的方向。
我现在对 AI 进入设计工作流的期待,其实很简单。
1. 我希望 AI 能把重复、费力气的事情先接过去。
比如资料整理、需求拆解、竞品框架、状态枚举、方案初稿、视觉方向发散。这些工作不是没有价值,但它们很耗精力。如果 AI 能先做一轮,设计师就能把更多时间留给真正需要判断的地方。
2. 我希望慢慢打造一套自动化的设计工作流。
但我现在也意识到,自动化不能一上来就追求完整。前提是每个环节都要相对稳定。
比如:需求分析能不能稳定输出;竞品分析能不能稳定提炼;方案发散能不能稳定不跑偏;视觉诊断能不能稳定拆问题;设计文档能不能稳定补状态。
只有这些环节稳定了,自动化才有意义。否则,只是把不稳定的结果更快地产出来。这不是提效,反而会增加返工。
所以我现在对 AI+UI/UX 工作流的理解是:
先让 AI 在单点能力上稳定,再把它串成流程。
GPT Image2 最难的不是出图,而是如何在真实 UI 项目里,变成一个可控、稳定、能被设计师调度的工具。
AI 不是让设计师少思考,而是逼着设计师把自己的判断说清楚。
你越能定义问题、拆清边界、判断方向,AI 才越能成为工具,而不是开盲盒。

复制本文链接 文章为作者独立观点不代表优设网立场,未经允许不得转载。
风筝KK
11.9w人气 4文章






发评论!每天赢奖品
点击 登录 后,在评论区留言,系统会随机派送奖品
2012年成立至今,是国内备受欢迎的设计师平台,提供奖品赞助 联系我们
UI设计精品必修课
已累计诞生 793 位幸运星
发表评论 为下方 2 条评论点赞,解锁好运彩蛋
↓ 下方为您推荐了一些精彩有趣的文章热评 ↓